GPT-5.4 Just Landed — How Does It Stack Up Against Opus 4.6, Grok and Gemini 3.1 Pro?
OpenAI dropped GPT-5.4 on March 5th and it's a pretty significant step up from 5.2. The headline numbers: 33% fewer factual errors per claim, 18% fewer errors overall, and a 272K context window. They also baked in native computer use that actually beat human performance on desktop tasks — 75% on OSWorld vs. 72.4% for humans.
But the real question is how it compares to what Anthropic, Google, and xAI are shipping right now.
Here's the benchmark data across three key categories:
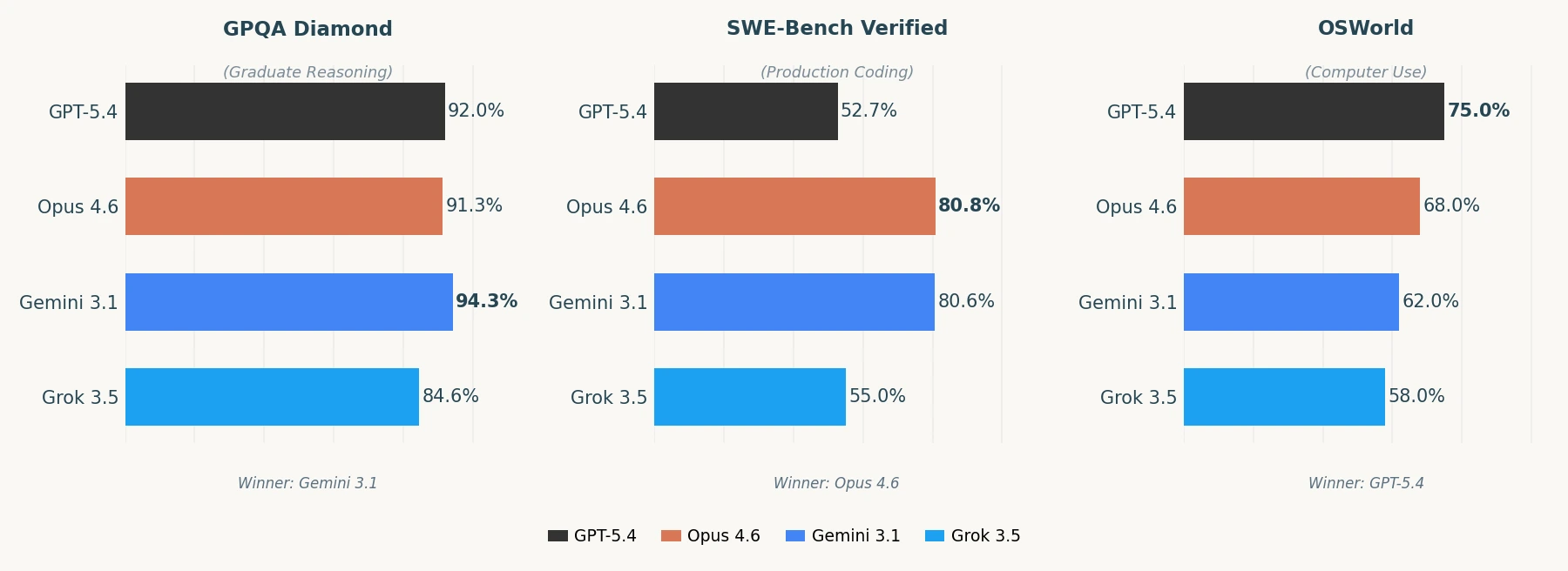
Each model basically owns a different lane:
GPT-5.4 is strongest at knowledge work and computer use. It scored 83% on GDPval, matching professionals across 44 different occupations. If you need an AI that can navigate software, fill out spreadsheets, and handle desktop tasks, this is the one.
Claude Opus 4.6 still holds the crown for coding. 80.8% on SWE-Bench Verified means it's the best at finding and fixing real production bugs. If you're building software or doing anything code-heavy, Opus hasn't been dethroned.
Gemini 3.1 Pro quietly dominates reasoning at a fraction of the price. 94.3% on GPQA Diamond and 77.1% on ARC-AGI-2 for abstract reasoning, and Google is charging $2/$12 per million tokens. That's roughly 5x cheaper than Opus.
Grok 3.5 is solid on math and reasoning from scratch but trails on production coding (55% SWE-Bench). If you're doing heavy computational work or research-style problems, Grok holds its own. For software engineering tasks, it's a tier below Opus and Gemini.
The 2M token context window on Gemini is also hard to ignore if you're working with large documents or codebases. Opus tops out at 200K standard (1M in beta).
Honestly, there's no single winner anymore. The smart play for anyone building products is to route different tasks to different models — coding to Opus, reasoning to Gemini, knowledge work to GPT-5.4. The days of one model to rule them all are probably over.
Anyone here already testing 5.4 in production?
0 Comments
No comments yet. Be the first to reply!