Grok 4.20 Just Dropped. Here's How It Actually Stacks Up.
xAI released Grok 4.20 on March 8, and the claims are big: record-low hallucination rates, a four-agent architecture, and benchmark scores that put it in the conversation with GPT-5.4, Claude Opus 4.6, and Gemini 3.1 Pro. I built TrustHub on AI tools, so when a new frontier model drops, I want to know if it's real or if it's just another press release.
So I pulled the benchmarks.
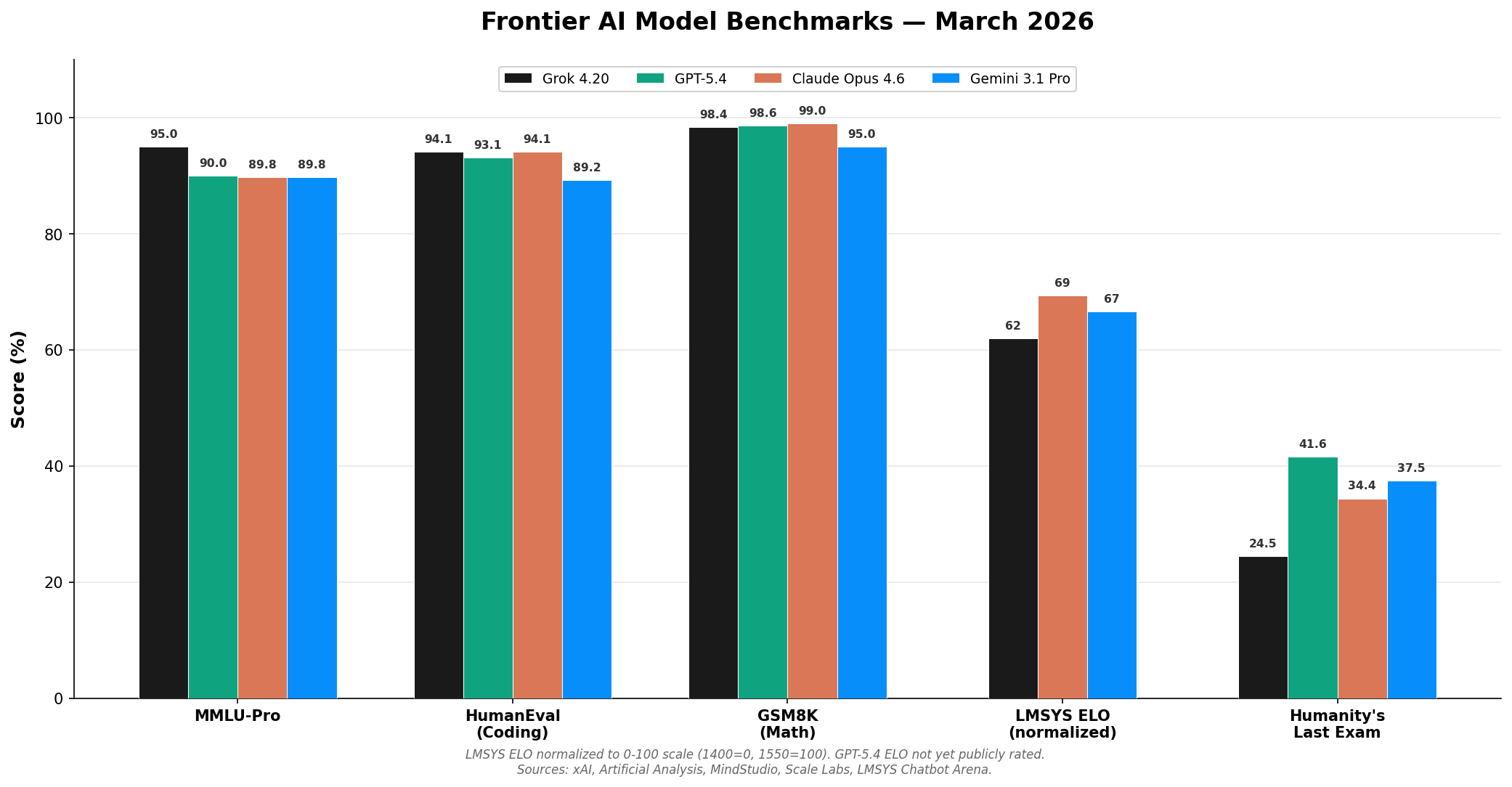
The Numbers
On MMLU-Pro — the harder version of the standard knowledge test — Grok 4.20 scored 95.0% according to xAI's published benchmarks, which is notably ahead of GPT-5.4 (90.0%), Claude Opus 4.6 (89.8%), and Gemini 3.1 Pro (89.8%) (Artificial Analysis). That's a real gap. Five points at this level isn't noise.
On HumanEval, which tests coding ability, it's tighter. Grok 4.20 hit 94.1%, GPT-5.4 came in at 93.1%, and Claude Opus 4.6 matched at 94.1% (xAI, MindStudio). All three are within spitting distance.
Math is where Grok flexes. GSM8K — a grade-school math benchmark — Grok scored 98.4% versus Gemini 3.1 Pro's 95.0% (Artificial Analysis). That's near-perfect. On the harder MATH benchmark (competition-level problems), Grok posted 92.0%.
On the LMSYS Chatbot Arena — the ELO-based ranking where real users blind-test models — Grok 4.20 sits at 1493. Claude Opus 4.6 leads at 1504, with Gemini 3.1 Pro at 1500 (LMSYS). So users prefer Claude and Gemini slightly, but it's close.
Where Grok Falls Short
Humanity's Last Exam — a benchmark designed to be the hardest test in AI, built by thousands of experts — tells a different story. Grok 4.20 scored 24.5%. Gemini 3 Pro hit 37.5%. Claude Opus 4.6 got 34.4%. GPT-5.4 landed at 41.6% (Scale Labs). On the hardest reasoning tasks, Grok is notably behind.
The Intelligence Index — a composite score from WinBuzzer — puts Grok at 48 out of 100, while Gemini 3.1 Pro and GPT-5.4 both score 57. That's a real gap on abstract reasoning and higher-order thinking.
So the picture is nuanced. Grok leads on knowledge (MMLU-Pro) and math. It's competitive on coding. But on the kinds of problems that require deep reasoning and creative problem-solving, it trails the field.
What Makes It Different
The architecture is interesting. Grok 4.20 runs a four-agent system under the hood: Grok coordinates, Harper fact-checks using real-time X (Twitter) data, Benjamin handles logic and coding, and Lucas handles creative tasks. The idea is that specialized agents cross-check each other, which is how xAI claims to have achieved a 78% non-hallucination rate on the Omniscience benchmark — beating every other frontier model on that specific metric (WinBuzzer).
The specs are competitive: 2 million token context window, 234 tokens per second, 131,000 token output limit. Pricing is $2 per million input tokens and $6 per million output, which is in line with what OpenAI and Anthropic charge.
It's built on xAI's Colossus cluster — 200,000 GPUs. That's a serious amount of compute. And it's trained on X data, which is both an advantage (real-time information) and a question mark (the quality of discourse on X is... variable).
What I Actually Care About
I don't pick my tools based on benchmarks. I pick them based on what helps me build things. I used Claude to build TrustHub. I've tried GPT for various tasks. I've used Gemini for research. The model that helps me ship real work is the one I care about.
Benchmarks tell you what a model can do in controlled conditions. They don't tell you how it handles your weird edge case at 2am when you're debugging something and you just need it to understand what you're trying to do.
That said, the hallucination reduction is worth watching. If Grok's four-agent system actually delivers on the "less bullshit" promise, that matters more to me than a few points on a math test. The worst thing an AI tool can do isn't be slow or expensive — it's be confidently wrong.
Whether Grok 4.20 becomes my daily driver remains to be seen. But the fact that we now have four legitimate frontier models competing this hard? That's good for everyone building with these tools.
Data sources: xAI — Grok 4.20 model specifications, Artificial Analysis — MMLU-Pro and benchmark evaluations, MindStudio — GPT-5.4 vs Claude 4.6 vs Gemini 3.1 Pro comparison, Scale Labs — Humanity's Last Exam leaderboard, LMSYS Chatbot Arena — ELO ratings, WinBuzzer — Intelligence Index and hallucination benchmarks.
0 Comments
No comments yet. Be the first to reply!